网络相关
http状态码?
- 1XX:信息状态码
- 100 Continue:客户端应当继续发送请求。这个临时相应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求万仇向客户端发送一个最终响应
- 101 Switching Protocols:服务器已经理解力客户端的请求,并将通过Upgrade消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到Upgrade消息头中定义的那些协议。
- 2XX:成功状态码
- 200 OK:请求成功,请求所希望的响应头或数据体将随此响应返回
- 201 Created:
- 202 Accepted:
- 203 Non-Authoritative Information:
- 204 No Content:
- 205 Reset Content:
- 206 Partial Content:
- 3XX:重定向
- 300 Multiple Choices:
- 301 Moved Permanently:
- 302 Found:
- 303 See Other:
- 304 Not Modified:
- 305 Use Proxy:
- 306 (unused):
- 307 Temporary Redirect:
- 4XX:客户端错误
- 400 Bad Request:
- 401 Unauthorized:
- 402 Payment Required:
- 403 Forbidden:
- 404 Not Found:
- 405 Method Not Allowed:
- 406 Not Acceptable:
- 407 Proxy Authentication Required:
- 408 Request Timeout:
- 409 Conflict:
- 410 Gone:
- 411 Length Required:
- 412 Precondition Failed:
- 413 Request Entity Too Large:
- 414 Request-URI Too Long:
- 415 Unsupported Media Type:
- 416 Requested Range Not Satisfiable:
- 417 Expectation Failed:
- 5XX: 服务器错误
- 500 Internal Server Error:
- 501 Not Implemented:
- 502 Bad Gateway:
- 503 Service Unavailable:
- 504 Gateway Timeout:
- 505 HTTP Version Not Supported:
cookie和session的区别
- cookie数据存放在客户的浏览器上,session数据放在服务器上
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。用户验证这种场合一般会用 session
- session保存在服务器,客户端不知道其中的信息;反之,cookie保存在客户端,服务器能够知道其中的信息
- session会在一定时间内保存在服务器上,当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie
- session中保存的是对象,cookie中保存的是字符串
- session不能区分路径,同一个用户在访问一个网站期间,所有的session在任何一个地方都可以访问到,而cookie中如果设置了路径参数,那么同一个网站中不同路径下的cookie互相是访问不到的
localStorage,sessionStorage和cookie的区别
数据存储方面
- cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递。cookie数据还有路径(path)的概念,可以限制cookie只属于某个路径下
sessionStorage和localStorage不会自动把数据发送给服务器,仅在本地保存。
存储数据大小
- 存储大小限制也不同,cookie数据不能超过4K,同时因为每次http请求都会携带cookie、所以cookie只适合保存很小的数据,如会话标识。
sessionStorage和localStorage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大
数据存储有效期
- sessionStorage:仅在当前浏览器窗口关闭之前有效;
- localStorage:始终有效,窗口或浏览器关闭也一直保存,本地存储,因此用作持久数据;
- cookie:只在设置的cookie过期时间之前有效,即使窗口关闭或浏览器关闭
作用域不同
- sessionStorage不在不同的浏览器窗口中共享,即使是同一个页面;
- localstorage在所有同源窗口中都是共享的;也就是说只要浏览器不关闭,数据仍然存在
- cookie: 也是在所有同源窗口中都是共享的.也就是说只要浏览器不关闭,数据仍然存在
同源策略是?
同domain(或ip),同端口,同协议视为同一个域,一个域内的脚本仅仅具有本域内的权限,可以理解为本域脚本只能读写本域内的资源,而无法访问其它域的资源。这种安全限制称为同源策略。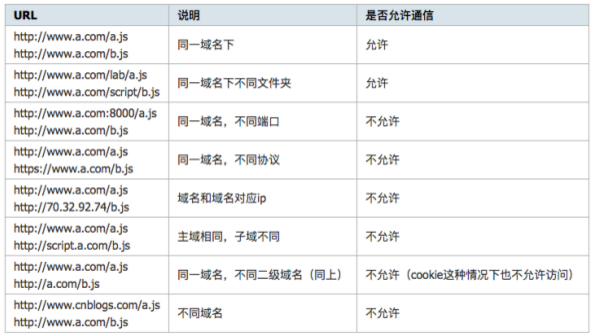
如何跨域通信
两个不同源的脚本通信就是跨域,方法主要有以下几种:
JSONP
JSONP全称为:JSON with Padding,可用于解决主流浏览器的跨域数据访问的问题。
Web 页面上调用 js 文件不受浏览器同源策略的影响,所以通过 Script 便签可以进行跨域的请求:
- 首先前端先设置好回调函数,并将其作为 url 的参数。
- 服务端接收到请求后,通过该参数获得回调函数名,并将数据放在参数中将其返回
- 收到结果后因为是 script 标签,所以浏览器会当做是脚本进行运行,从而达到跨域获取数据的目的。
优点:
- 它不像XMLHttpRequest 对象实现 Ajax 请求那样受到同源策略的限制
- 兼容性很好,在古老的浏览器也能很好的运行
- 不需要 XMLHttpRequest 或 ActiveX 的支持;并且在请求完毕后可以通过调用 callback 的方式回传结果。
缺点:
- 它支持 GET 请求而不支持 POST 等其它类行的 HTTP 请求。
- 它只支持跨域 HTTP 请求这种情况,不能解决不同域的两个页面或 iframe 之间进行数据通信的问题
CORS
CORS 是一个 W3C 标准,全称是”跨域资源共享”(Cross-origin resource sharing)它允许浏览器向跨源服务器,发出 XMLHttpRequest 请求,从而克服了 ajax 只能同源使用的限制。
CORS 需要浏览器和服务器同时支持才可以生效,对于开发者来说,CORS 通信与同源的 ajax 通信没有差别,代码完全一样。浏览器一旦发现 ajax 请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
优点:
- 使用简单方便,更为安全
- 支持 POST 请求方式
缺点:
- CORS 是一种新型的跨域问题的解决方案,存在兼容问题,仅支持 IE 10 以上
Server Proxy
服务器代理,顾名思义,当你需要有跨域的请求操作时发送请求给后端,让后端帮你代为请求,然后最后将获取的结果发送给你。
从输入URL到页面加载发生了什么
- DNS解析
- TCP连接
- 发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析渲染页面
- 连接结束
DNS解析
DNS服务器通过url地址递归查找到服务器ip的过程
域名解析的过程是逐级查询的
- 浏览器缓存: 首先会向浏览器的缓存中读取上一次访问的记录,在chrome可以通过地址栏中输入chrome://net-internals/#dns查看缓存的当前状态
- 操作系统缓存:查找存储在系统运行内存中的缓存。在mac中可以通过下面的命令清除系统中的DNS缓存。
- 在host文件中查找:如果在缓存中都查找不到的情况下,就会读取系统中预设的host文件中的设置。
- 路由器缓存:有些路由器也有DNS缓存的功能,访问过的域名会存在路由器上。
- ISP DNS缓存:互联网服务提供商(如中国电信)也会提供DNS服务,比如比较著名的 114.114.114.114,在本地查找不到的情况下,就会向ISP进行查询,ISP会在当前服务器的缓存内查找是否有记录,如果有,则返回这个IP,若没有,则会开始向根域名服务器请求查询。
- 顶级DNS服务器/根DNS服务器:根域名收到请求后,会判别这个域名(.com)是授权给哪台服务器管理,并返回这个顶级DNS服务器的IP。请求者收到这台顶级DNS的服务器IP后,会向该服务器发起查询,如果该服务器无法解析,该服务器就会返回下一级的DNS服务器IP(nicefilm.com),本机继续查找,直到服务器找到(www.nicefilm.com)的主机。
TCP 连接
拿到了要请求的资源服务器IP后,浏览器通过操作OS的socket与服务器进行TCP连接
三次握手
- 第一次,本机将标识位 SYN 置为 1, seq = x(Sequence number)发送给服务端。此时本机状态为SYN-SENT
- 第二次,服务器收到包之后,将状态切换为SYN-RECEIVED,并将标识位 SYN 和 ACK都置为1, seq = y, ack = x + 1, 并发送给客户端。
- 第三次,客户端收到包后,将状态切换为ESTABLISHED,并将标识位ACK置为1,seq = x + 1, ack = y + 1, 并发送给服务端。服务端收到包之后,也将状态切换为ESTABLISHED。
发送HTTP请求
发送HTTP请求的过程就是构建HTTP请求报文并通过TCP协议中发送到服务器指定端口(HTTP协议80/8080, HTTPS协议443)。HTTP请求报文是由三部分组成: 请求行, 请求报头和请求正文。
- 请求行:请求行中包括请求的方法,路径和协议版本。
- 请求头:请求头中包含了请求的一些附加的信息,一般是以键值的形式成对存在,比如设置请求文件的类型accept-type,以及服务器对缓存的设置。
- 空行:协议中规定请求头和请求主体间必须用一个空行隔开
- 请求主体:对于post请求,所需要的参数都不会放在url中,这时候就需要一个载体了,这个载体就是请求主题。
服务器处理请求并返回HTTP报文
服务端收到请求之后,会根据url匹配到的路径做相应的处理,最后返回浏览器需要的页面资源。浏览器会收到一个响应报文,而所需要的资源就就在报文主体上。与请求报文相同,响应报文也有与之对应的起始行、首部、空行、报文主体,不同的地方在于包含的东西不一样。
- 响应行:响应报文的起始行同样包含了协议版本,与请求的起始行不同的是其包含的还有状态码和状态码的原因短语。
- 响应头:对应请求报文中的请求头,格式一致,但是各自有不同的首部。也有一起用的通用首部。
- 空行
- 报文主体:请求所需要的资源。
浏览器解析渲染页面
至此浏览器已经拿到了一个HTML文档,并为了呈现文档而开始解析。呈现引擎开始工作,基本流程如下(以webkit为例)
- 通过HTML解析器解析HTML文档,构建一个DOM Tree,同时通过CSS解析器解析HTML中存在的CSS,构建Style Rules,两者结合形成一个Attachment。
- 通过Attachment构造出一个呈现树(Render Tree)
- Render Tree构建完毕,进入到布局阶段(layout/reflow),将会为每个阶段分配一个应出现在屏幕上的确切坐标。
- 最后将全部的节点遍历绘制出来后,一个页面就展现出来了。
连接结束
现在的页面为了优化请求的耗时,默认都会开启持久连接(keep-alive),那么一个TCP连接确切关闭的时机,是这个tab标签页关闭的时候。这个关闭的过程就是著名的四次挥手。关闭是一个全双工的过程,发包的顺序的不一定的。一般来说是客户端主动发起的关闭,过程如下。
假如最后一次客户端发出的数据seq = x, ack = y;
- 客户端发送一个FIN置为1的包,ack = y, seq = x + 1,此时客户端的状态为 FIN_WAIT_1
- 服务端收到包后,状态切换为CLOSE_WAIT发送一个ACK为1的包, ack = x + 2。客户端收到包之后状态切换为FNI_WAIT_2
- 服务端处理完任务后,向客户端发送一个 FIN包,seq = y; 同时将自己的状态置为LAST_ACK
- 客户端收到包后状态切换为TIME_WAIT,并向服务端发送ACK包,ack = y + 1,等待2MSL后关闭连接。
OSI 七层网络模型

http缓存
请求是浏览器的一个优化点,我们可以通过缓存来减少不必要的请求,进而加快页面的呈现。通过简单地设置http头部可以使用缓存的功能。一般来说有三种设置的方式
Last-Modify(响应头) + If-Modified-Since(请求头)
服务器在返回资源的时候设置Last-Modify当前资源最后一次修改的时间,浏览器会把这个时间保存下来,在下次请求的时候,请求头部If-Modified-Since 会包含这个时间,服务端收到请求后,会比对资源最后更新的时间是否在If-Modified-Since设置的时间之后,如果不是,返回304状态码,浏览器将从缓存中获取资源。反之返回200和资源内容。
ETag(响应头) + If-None-Match(请求头)
根据资源标识符来确定文件是否存在修改,服务器每一次返回资源,都会在Etag中存放资源的标识符,浏览器收到这个标识符,在下一次请求的时候将标识符放在If-None-Match中,服务端将判断是否匹配,如果不匹配,返回200以及新的资源,反之返回304,浏览器从缓存中获取资源
Cache-Control/Expires(响应头)
首先这不是一种方法,而是协议更替中的一种演化。
在http 1.0的时代,我们基于Pragma 和 Expires 控制缓存的生命周期。我们可以通过设置Pragma为no-cache关闭缓存功能,同样也可以在Expires中设置一个缓存失效的时间。需要注意的是,这个失效的时间是相对于服务器的实践而言的,如果人为地改变了客户端的时间,是会导致缓存失效的。
所以,为了解决这个问题,HTTP1.1的协议加入了Cache-Control,通过设置Cache-Control的max-age可以控制缓存的周期。在这个周期内,资源是新鲜的,浏览器再一次需要使用资源的时候,就不会发出请求了
TCP 为什么是三次握手,而不是两次或四次?
核心思想:既要保证数据可靠传输,又要提高传输的效率,而用三次恰恰可以满足以上两方面的需求!
四次握手的过程:
- A 发送同步信号SYN + A’s Initial sequence number
- B 确认收到A的同步信号,并记录 A’s ISN 到本地,命名 B’s ACK sequence number
- B发送同步信号SYN + B’s Initial sequence number
- A确认收到B的同步信号,并记录 B’s ISN 到本地,命名 A’s ACK sequence number
很显然2和3这两个步骤可以合并,只需要三次握手,可以提高连接的速度与效率。
二次握手的过程:
- A 发送同步信号SYN + A’s Initial sequence number
- B发送同步信号SYN + B’s Initial sequence number + B’s ACK sequence number
这里有一个问题,A与B就A的初始序列号达成了一致,这里是1000。但是B无法知道A是否已经接收到自己的同步信号,如果这个同步信号丢失了,A和B就B的初始序列号将无法达成一致。
HTML相关
html语义化?
HTML标签的语义化是指:通过使用包含语义的标签(如h1-h6)恰当地表示文档结构。
- 去掉样式后页面呈现清晰的结构
- 盲人使用读屏器更好地阅读
- 搜索引擎更好地理解页面,有利于收录
- 便团队项目的可持续运作及维护
viewport的常见设置有哪些
viewport常常使用在响应式开发以及移动web开发中,viewport顾名思义就是用来设置视口,主要是规定视口的宽度、视口的初始缩放值、 视口的最小缩放值、视口的最大缩放值、是否允许用户缩放等。一个常见的viewport设置如下:1
<meta name="viewport" content="initial-scale=1,maximum-scale=1,user-scalable=no,width=device-width" />
- initial-scale:初始缩放比例
- maximum-scale:允许缩放的最大比例
- minimum-scale:允许缩放的最小比例
- user-scalable:是否允许手动缩放
H5新增?
- 新的元素:section, video, progress, nav, meter, time, aside, canvas, command, datalist, details, embed, figcaption, figure, footer, header, hgroup, keygen, mark, output, rp, rt, ruby, source, summary, wbr。
CSS相关
盒模型?
盒模型(box model)是CSS中的一个重要概念,它是元素大小的呈现方式。需要记住的是:”every element in web design is a rectangular box”。

常用选择器?
- *通用选择器:选择所有元素,不参与计算优先级,兼容性IE6+
- #X id选择器:选择id值为X的元素,兼容性:IE6+
- .X 类选择器: 选择class包含X的元素,兼容性:IE6+
- X Y后代选择器: 选择满足X选择器的后代节点中满足Y选择器的元素,兼容性:IE6+
- X 元素选择器: 选择标所有签为X的元素,兼容性:IE6+
- :link,:visited,:focus,:hover,:active链接状态: 选择特定状态的链接元素,顺序LoVe HAte,兼容性: IE4+
- X + Y直接兄弟选择器:在X之后第一个兄弟节点中选择满足Y选择器的元素,兼容性: IE7+
- X > Y子选择器: 选择X的子元素中满足Y选择器的元素,兼容性: IE7+
- X ~ Y兄弟: 选择X之后所有兄弟节点中满足Y选择器的元素,兼容性: IE7+
- [attr] 属性选择器
选择器优先级如何确定?
- 千位:声明在style属性中,所谓的内联属性 + 1
- 百位:ID选择器 + 1
- 十位:类选择器+1、属性选择器+1、或者伪类+1
- 个位:元素选择器+1、伪元素+1
如何居中?
水平居中
块级元素
margin: auto, 设置块级元素的 width 可以防止它从左到右撑满整个容器。然后你就可以设置左右外边距为 auto 来使其水平居中。元素会占据你所指定的宽度,然后剩余的宽度会一分为二成为左右外边距。
1
2
3
4#main {
width: 600px;
margin: 0 auto;
}flex布局
1
2
3
4.parent {
display: flex;
justify-content: center;
}CSS3 transform
1
2
3
4
5
6
7
8.parent {
position: relative;
}
.child {
position: absolute;
left: 50%;
transform: translateX(-50%);
}display设置为tabel-cell
内联元素
1 | text-align: center |
垂直居中
块级元素
不知道自己高度和父容器高度
1
2
3
4
5
6
7
8parentElement{
position:relative;
}
childElement{
position: absolute;
top: 50%;
transform: translateY(-50%);
}父容器下只有一个元素,且父元素设置了高度
1
2
3
4
5
6
7
8parentElement{
height:xxx;
}
.childElement {
position: relative;
top: 50%;
transform: translateY(-50%);
}Flex布局
1
2
3
4
5parentElement{
display:flex;/*Flex布局*/
display: -webkit-flex; /* Safari */
align-items:center;/*指定垂直居中*/
}table布局(不推荐),display:table-cell,同时设置vertical-align:middle
单行元素
- line-height = height
- inline或者table-cell
vertical-align:middle;
BFC?
BFC(Block formatting context)直译为”块级格式化上下文”。它是一个独立的渲染区域,只有 Block-level box 参与, 它规定了内部的 Block-level Box 如何布局,并且与这个区域外部毫不相干。
简单来说,CSS 里的布局和渲染都是以 Box 为单位的,不同的 Box 有不同的布局规则,而 BFC 是其中的一种,相似的还有 IFC 和 CSS3 中增加的 GFC 和 FFC,这里就不深入介绍了。
BFC布局规则
BFC 的布局遵从如下规则:
- 内部的 Box 会在垂直方向,一个接一个地放置。
- Box 垂直方向的距离由 margin 决定。属于同一个 BFC 的两个相邻 Box 的 margin 会发生重叠
- 每个元素的 margin box 的左边, 与包含块 border box 的左边相接触(对于从左往右的格式化,否则相反)。即使存在浮动也是如此。
- BFC 的区域不会与 float box 重叠。
- BFC 就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此。
- 计算BFC的高度时,浮动元素也参与计算。
哪些元素会生成BFC
- 根元素。
- float 属性不为 none。
- position 为 absolute 或 fixed。
- display 为 inline-block, table-cell, table-caption, flex, inline-flex。
- overflow 不为 visible(hidden, scroll, auto)。
重绘(repaint)和回流(reflow)是什么,如何避免?
DOM的变化影响到了元素的几何属性(宽高),浏览器重新计算元素的几何属性,其他元素的几何 属性和位置也会受到影响,浏览器需要重新构造渲染树,这个过程称为重排,浏览器将受到影响的部分 重新绘制到屏幕上的过程称为重绘。引起重排的原因有
- 调整窗口大小
- 字体大小
- 样式表变动
- 元素内容变化,尤其是输入控件
- CSS伪类激活,在用户交互过程中发生
- DOM操作,DOM元素增删、修改
- width, clientWidth, scrollTop等布局宽高的计算
减少重绘和重排的方法:
- 避免频繁读取元素几何属性
- 使用cssText或者className一次性改变属性
- 使用fragment
- 对于多次重排的元素,如动画,使用绝对定位脱离文档流,让他的改变不影响到其他元素
如何清除浮动?
- overflow: auto
- 伪元素
1
2
3
4
5.clearfix::after {
content:"";
display:block;
clear: both;
}
JavaScript相关
什么是事件循环(EVENT LOOP)?
我们常常说js是单线程的,是指js执行引擎是单线程的,除了这个单线程,还有一个 任务队列,在执行js代码的过程中,执行引擎遇到注册的延时方法,如定时器,DOM事件, 会将这些方法交给相应的浏览器模块处理,当这些延时方法有触发条件去触发的时候, 这些延时方法会被添加至任务队列,而这些任务队列中的方法只有js的主线程空闲了才会执行, 这也就是说我们常常用的定时器定的时间参数只是一个触发条件,具体多少时间后执行其实还需要看 js主线程空闲与否
执行上下文
简而言之,执行上下文是评估和执行 JavaScript 代码的环境的抽象概念。每当 Javascript 代码在运行的时候,它都是在执行上下文中运行。
执行上下文的类型
JavaScript 中有三种执行上下文类型。
- 全局执行上下文 — 这是默认或者说基础的上下文,任何不在函数内部的代码都在全局上下文中。它会执行两件事:创建一个全局的 window 对象(浏览器的情况下),并且设置 this 的值等于这个全局对象。一个程序中只会有一个全局执行上下文。
- 函数执行上下文 — 每当一个函数被调用时,都会为该函数创建一个新的上下文。每个函数都有它自己的执行上下文,不过是在函数被调用时创建的。函数上下文可以有任意多个。每当一个新的执行上下文被创建,它会按定义的顺序执行一系列步骤。
- Eval 函数执行上下文 — 执行在 eval函数内部的代码也会有它属于自己的执行上下文,但由于 JavaScript 开发者并不经常使用 eval,所以在这里我不会讨论它。
变量对象 作用域链 this
对于每个执行上下文,都有三个重要属性:
- 变量对象(Variable object,VO)
- 作用域链(Scope chain)
- this
变量对象
变量对象是与执行上下文相关的数据作用域,存储了在上下文中定义的变量和函数声明。
当进入执行上下文时,这时候还没有执行代码,
变量对象会包括:
- 函数的所有形参 (如果是函数上下文)
- 由名称和对应值组成的一个变量对象的属性被创建
- 没有实参,属性值设为 undefined
- 函数声明
- 由名称和对应值(函数对象(function-object))组成一个变量对象的属性被创建
- 如果变量对象已经存在相同名称的属性,则完全替换这个属性
- 变量声明
- 由名称和对应值(undefined)组成一个变量对象的属性被创建;
- 如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性
作用域链
当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做作用域链。
函数的作用域在函数定义的时候就决定了。
这是因为函数有一个内部属性 [[scope]],当函数创建的时候,就会保存所有父变量对象到其中,你可以理解 [[scope]] 就是所有父变量对象的层级链,但是注意:[[scope]] 并不代表完整的作用域链!
举个例子:1
2
3
4
5function foo() {
function bar() {
...
}
}
函数创建时,各自的[[scope]]为:1
2
3
4
5
6
7
8foo.[[scope]] = [
globalContext.VO
];
bar.[[scope]] = [
fooContext.AO,
globalContext.VO
];
this指向
- 作为对象调用时,指向该对象 obj.b(); // 指向obj
- 作为函数调用, var b = obj.b; b(); // 指向全局window
- 作为构造函数调用 var b = new Fun(); // this指向当前实例对象
- 作为call与apply调用 obj.b.apply(object, []); // this指向当前的object
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var value = 1;
var foo = {
value: 2,
bar: function () {
return this.value;
}
}
//示例1
console.log(foo.bar());//2
//示例2
console.log((foo.bar)());//2
//示例3
console.log((foo.bar = foo.bar)());//1
//示例4
console.log((false || foo.bar)());//1
//示例5
console.log((foo.bar, foo.bar)());//1
JS 原型是什么?
每一个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型”继承”属性。
protytype
每个函数都有一个 prototype 属性,指向了一个对象,这个对象正是调用该构造函数而创建的实例的原型对象
proto
每一个JavaScript对象(除了 null)都具有的一个属性,叫__proto__,这个属性会指向该对象的原型。
constructor
每个原型都有一个 constructor 属性指向关联的构造函数。
原型链
图中由相互关联的原型组成的链状结构就是原型链,也就是蓝色的这条线。
JS 如何实现继承?
原型链
1 | function Child() { |
ES6 class
1 | class Child extends Parent { |
new 做了几件事?
- 以构造器的 prototype 属性(注意与私有字段 [[prototype]] 的区分)为原型,创建新对象;
- 将 this 和调用参数传给构造器,执行;
- 如果构造器返回的是对象,则返回,否则返回第一步创建的对象。
闭包
MDN 对闭包的定义为:
闭包是指那些能够访问自由变量的函数。
那什么是自由变量呢?
自由变量是指在函数中使用的,但既不是函数参数也不是函数的局部变量的变量。
由此,我们可以看出闭包共有两部分组成:
闭包 = 函数 + 函数能够访问的自由变量
依靠作用域链,闭包可以在函数已经销毁的情况下依然访问到自由变量
必考题
1 | var data = []; |
答案是都是 3,让我们分析一下原因,
当执行 data[0] 函数的时候,data[0] 函数的作用域链为:1
2
3data[0]Context = {
Scope: [AO, globalContext.VO]
}
data[0]Context 的 AO 并没有 i 值,所以会从 globalContext.VO 中查找,i 为 3,所以打印的结果就是 3。
改成闭包之后:1
2
3
4
5
6
7
8
9
10
11
12
13var data = [];
for (var i = 0; i < 3; i++) {
data[i] = (function (i) {
return function(){
console.log(i);
}
})(i);
}
data[0]();
data[1]();
data[2]();
当执行 data[0] 函数的时候,data[0] 函数的作用域链发生了改变:1
2
3data[0]Context = {
Scope: [AO, 匿名函数Context.AO globalContext.VO]
}
匿名函数执行上下文的AO为:1
2
3
4
5
6
7
8
9匿名函数Context = {
AO: {
arguments: {
0: 0,
length: 1
},
i: 0
}
}
data[0]Context 的 AO 并没有 i 值,所以会沿着作用域链从匿名函数 Context.AO 中查找,这时候就会找 i 为 0,找到了就不会往 globalContext.VO 中查找了,即使 globalContext.VO 也有 i 的值(值为3),所以打印的结果就是0。
静态作用域与动态作用域
JavaScript 采用的是词法作用域(静态作用域),函数的作用域在函数定义的时候就决定了。
而与词法作用域相对的是动态作用域,函数的作用域是在函数调用的时候才决定的。
Promise
概念
所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。从语法上说,Promise 是一个对象,从它可以获取异步操作的消息。Promise 提供统一的 API,各种异步操作都可以用同样的方法进行处理。
使用
1 | // ajax函数将返回Promise对象: |
手写Ajax
1 | var request = new XLMHttpRequest(); |
XMLHttpRequest.readyState可能值:
- 0,表示 XMLHttpRequest 实例已经生成,但是实例的open()方法还没有被调用。
- 1,表示open()方法已经调用,但是实例的send()方法还没有调用,仍然可以使用实例的setRequestHeader()方法,设定 HTTP 请求的头信息。
- 2,表示实例的send()方法已经调用,并且服务器返回的头信息和状态码已经收到。
- 3,表示正在接收服务器传来的数据体(body 部分)。这时,如果实例的responseType属性等于text或者空字符串,responseText属性就会包含已经收到的部分信息。
- 4,表示服务器返回的数据已经完全接收,或者本次接收已经失败。
立即执行函数
立即执行函数模式是一种语法,可以让你的函数在定义后立即被执行1
2
3(function () {
alert('watch out!');
}());
这种模式有一些几部分组成:
- 使用函数表达式定义一个函数(函数声明不能起作用)
- 在结尾加上一对括号,让函数立即被执行
- 将整个函数包裹在一对括号中(只有在你不将函数赋值给一个变量的时候才需要)
好处
这种模式是非常有用的,因为它为你初始化代码提供了一个作用域的沙箱;
考虑一下下面这种常见的场景:
你的代码在页面代码加载完成之后,不得不执行一些设置工作,比如附加时间处理器,创建对象等等,
所有的这些工作只需要执行一次,所以没有理由创建一个可复用的命名的函数,
但这些代码也需要一些临时的变量,但初始化过程结束后,就再也不会被用到了,
所以将这些变量作为全局变量不是个好主意,所以我们需要立即执行函数——去将我们所有的代码包裹在它的局部作用域中,不会让任何变量泄露成全局变量;
深拷贝
1 | var cloneObj = function(obj){ |
数组去重
用indexOf
1
2
3
4
5
6
7
8
9
10
11
12
13
14var array = [1, 1, '1'];
function unique(array) {
var res = [];
for (var i = 0, len = array.length; i < len; i++) {
var current = array[i];
if (res.indexOf(current) === -1) {
res.push(current)
}
}
return res;
}
console.log(unique(array));indexOf + fliter
1
2
3
4
5
6
7
8
9
10var array = [1, 2, 1, 1, '1'];
function unique(array) {
var res = array.filter(function(item, index, array){
return array.indexOf(item) === index;
})
return res;
}
console.log(unique(array));用set
1
2
3
4
5
6
7var array = [1, 1, '1'];
function unique(array) {
return Array.from(new Set(array)) // or [...new Set(array)];
}
console.log(unique(array));先排序再判断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var array = [1, 1, '1'];
function unique(array) {
var res = [];
var sortedArray = array.concat().sort();
var seen;
for (var i = 0, len = sortedArray.length; i < len; i++) {
// 如果是第一个元素或者相邻的元素不相同
if (!i || seen !== sortedArray[i]) {
res.push(sortedArray[i])
}
seen = sortedArray[i];
}
return res;
}
console.log(unique(array));
用正则实现 string.trim()
1 | var myTrim = function(str) { |
js实现call, apply, bind
call
1
2
3
4
5
6
7
8
9
10
11
12
13
14Function.prototype.call = function (context) {
var context = context || window;
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context.fn(' + args +')');//args 会自动调用 Array.toString()
delete context.fn
return result;
}apply
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Function.prototype.apply = function (context, arr) {
var context = Object(context) || window;
context.fn = this;
var result;
if (!arr) {
result = context.fn();
}
else {
var args = [];
for (var i = 0, len = arr.length; i < len; i++) {
args.push('arr[' + i + ']');
}
result = eval('context.fn(' + args + ')')
}
delete context.fn
return result;
}bind
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20Function.prototype.bind2 = function (context) {
if (typeof this !== "function") {
throw new Error("Function.prototype.bind - what is trying to be bound is not callable");
}
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fNOP = function () {};
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(this instanceof fNOP ? this : context, args.concat(bindArgs));
}
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}
防抖函数
防抖的原理就是:你尽管触发事件,但是我一定在事件触发 n 秒后才执行,如果你在一个事件触发的 n 秒内又触发了这个事件,那我就以新的事件的时间为准,n 秒后才执行,总之,就是要等你触发完事件 n 秒内不再触发事件,我才执行,真是任性呐!1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25function debounce(func, wait, immediate) {
var timeout, result;
return function () {
var context = this;
var args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
timeout = setTimeout(function(){
timeout = null;
}, wait)
if (callNow) result = func.apply(context, args)
}
else {
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
return result;
}
}
节流函数
如果你持续触发事件,每隔一段时间,只执行一次事件。
根据首次是否执行以及结束后是否执行,效果有所不同,实现的方式也有所不同。
使用时间戳
1 | function throttle(func, wait) { |
使用定时器
1 | // 第二版 |
DOM
DOM 事件模型是什么
DOM事件模型分为捕获和冒泡。一个事件发生后,会在子元素和父元素之间传播(propagation)。这种传播分成三个阶段。
- 捕获阶段:事件从window对象自上而下向目标节点传播的阶段;
- 目标阶段:真正的目标节点正在处理事件的阶段;
- 冒泡阶段:事件从目标节点自下而上向window对象传播的阶段。

事件委托是什么?有什么好处?
把一个或者一组元素的事件委托到它的父层或者更外层元素上,真正绑定事件的是外层元素,当事件响应到需要绑定的元素上时,会通过事件冒泡机制从而触发它的外层元素的绑定事件上,然后在外层元素上去执行函数。
优点:
- 减少内存消耗
- 动态绑定事件